Hi there! I'm a third-year undergraduate student at Peking University, majoring in Computer Science.
Currently, I am a visiting student at BAIR at UC Berkeley, advised by Prof. Trevor Darrell.
Prior to this, I was a research intern at the HMI Lab at Peking University, advised by Prof. Shanghang Zhang.
My research interests lie in the application of multimodal large models, specifically VLA models, in robot manipulation.
I'm interested in Computer Vision, Robot Learning and Embodied Large Multimodal Models. My research focuses on how to enhance large multimodal models to better reason about the physical world and develop effective task planning. Some papers are highlighted.
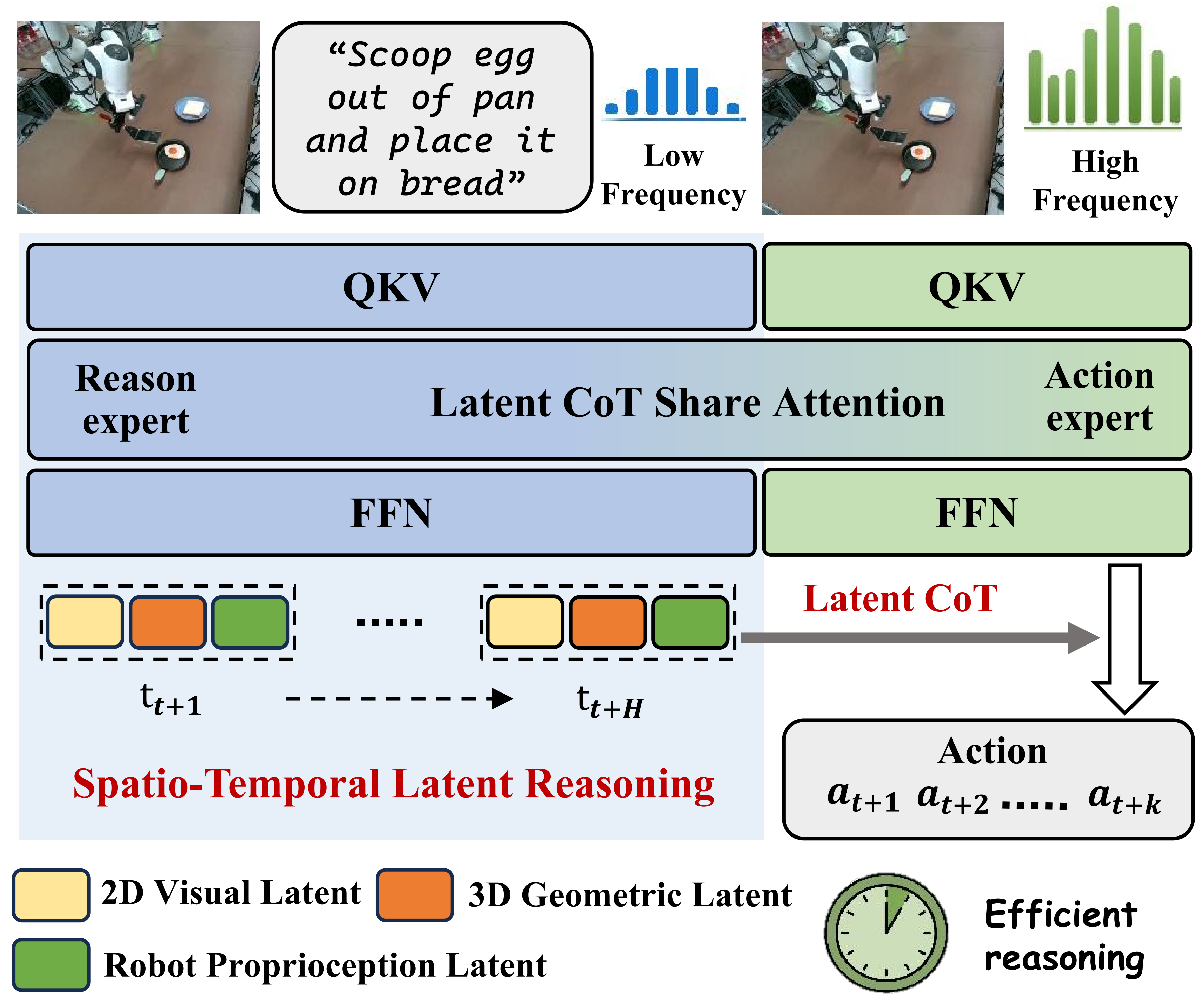
A VLA model that enables efficient reasoning before acting through a Latent Spatio-Temporal Chain-of-Thought (CoT), capturing fine-grained physical and robotic dynamics that are often difficult to verbalize.
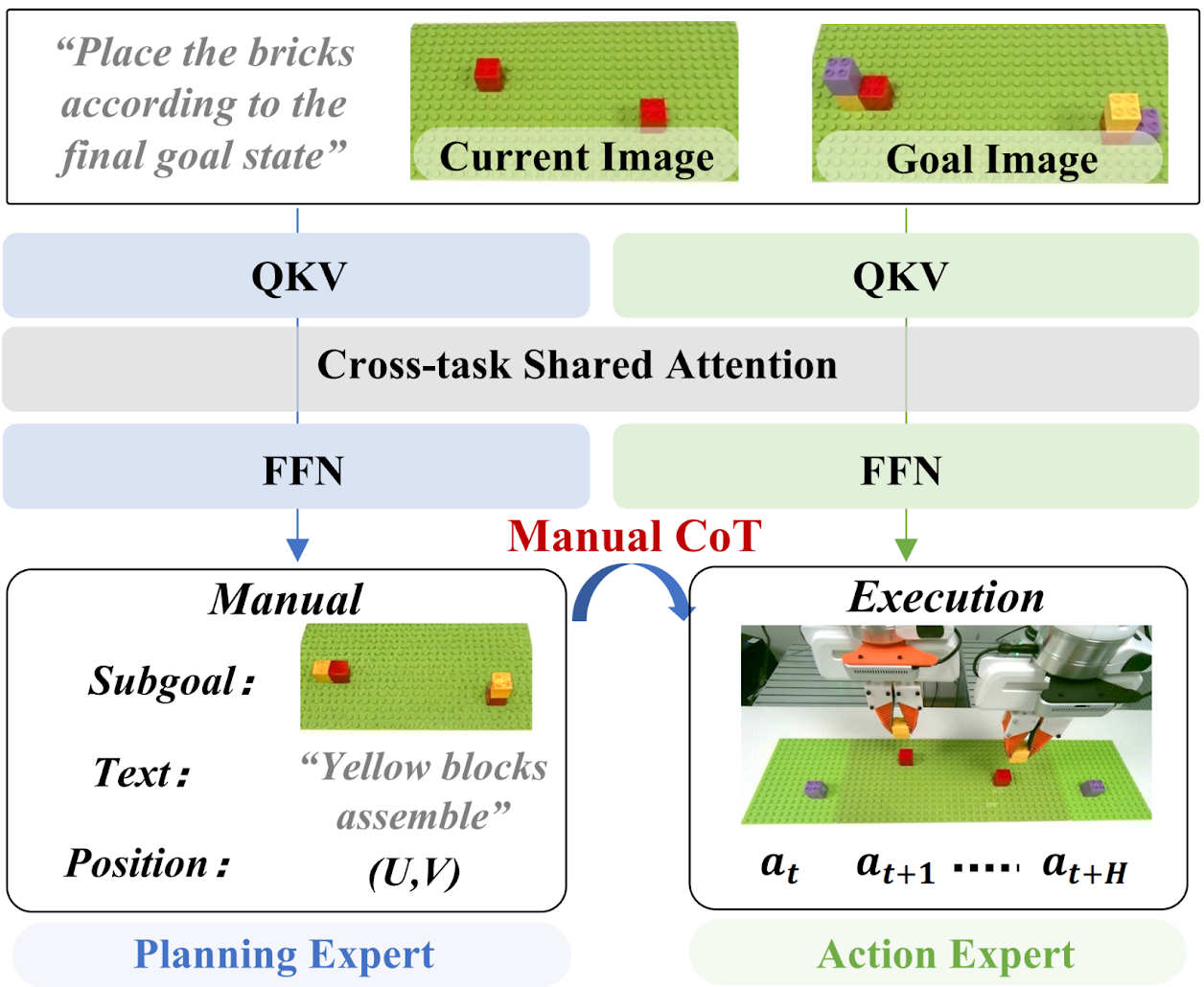
A unified VLA framework built upon a Mixture-of-Transformers (MoT) architecture, enabling coherent collaboration between multimodal manual generation and action execution.
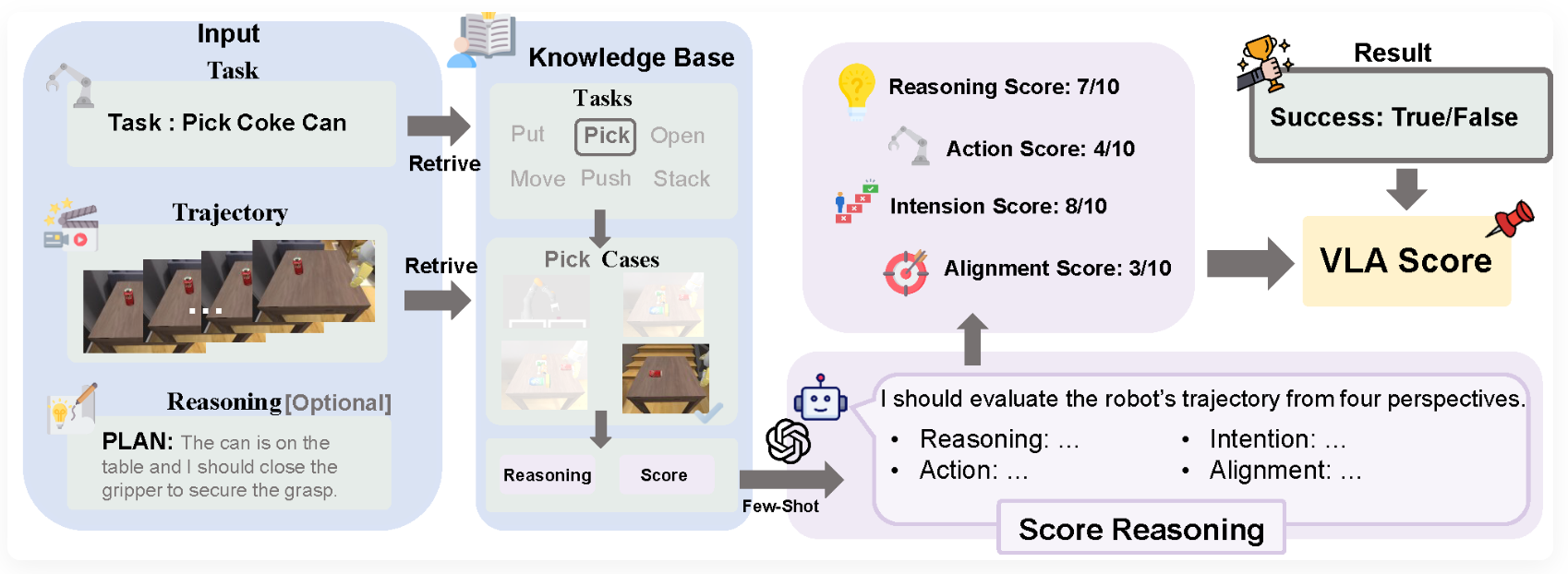
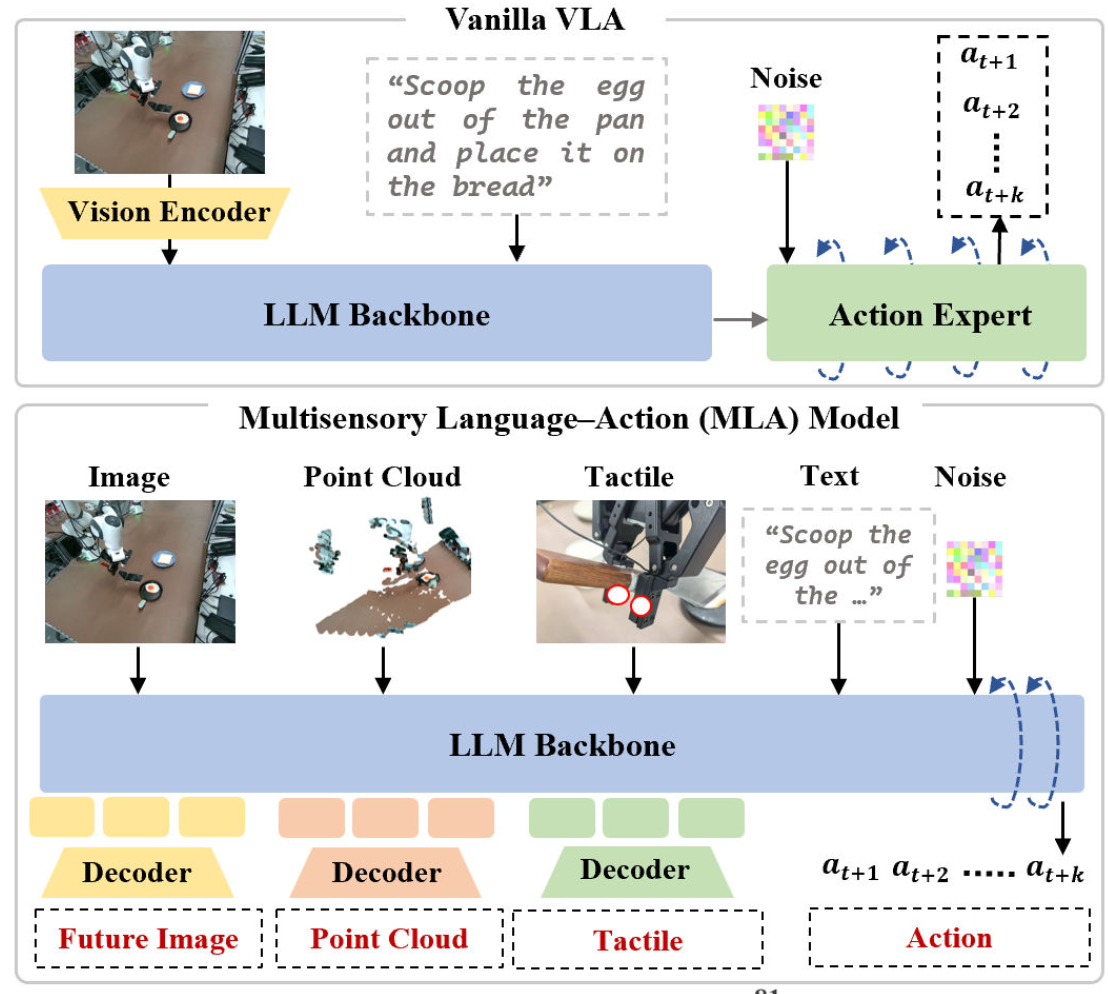
A multisensory language-action (MLA) model that collaboratively perceives heterogeneous sensory modalities and predicts future multisensory objectives to facilitate physical world modeling.
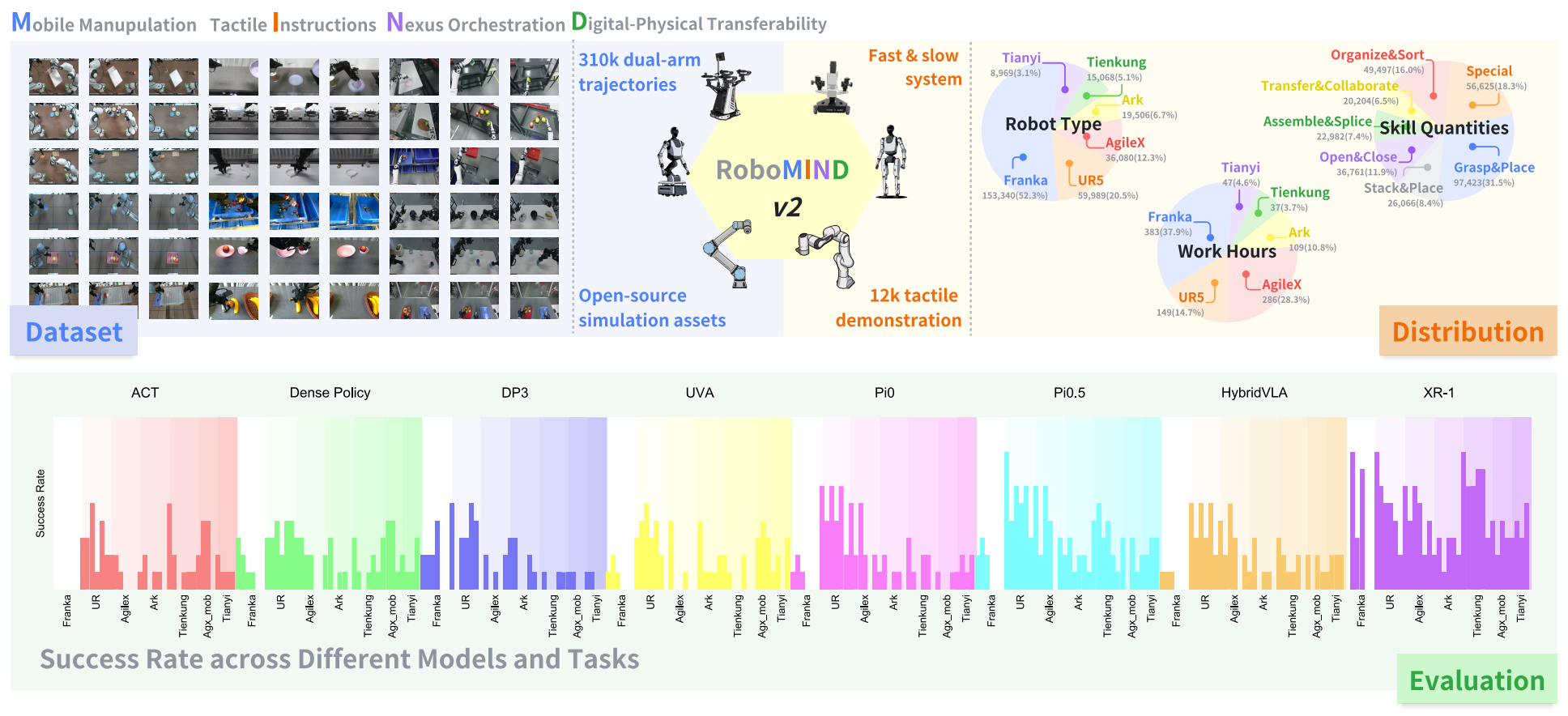
RoboMIND 2.0 is a comprehensive real-world dataset comprising over 310K dual-arm manipulation trajectories collected across six distinct robot embodiments and 739 complex tasks.
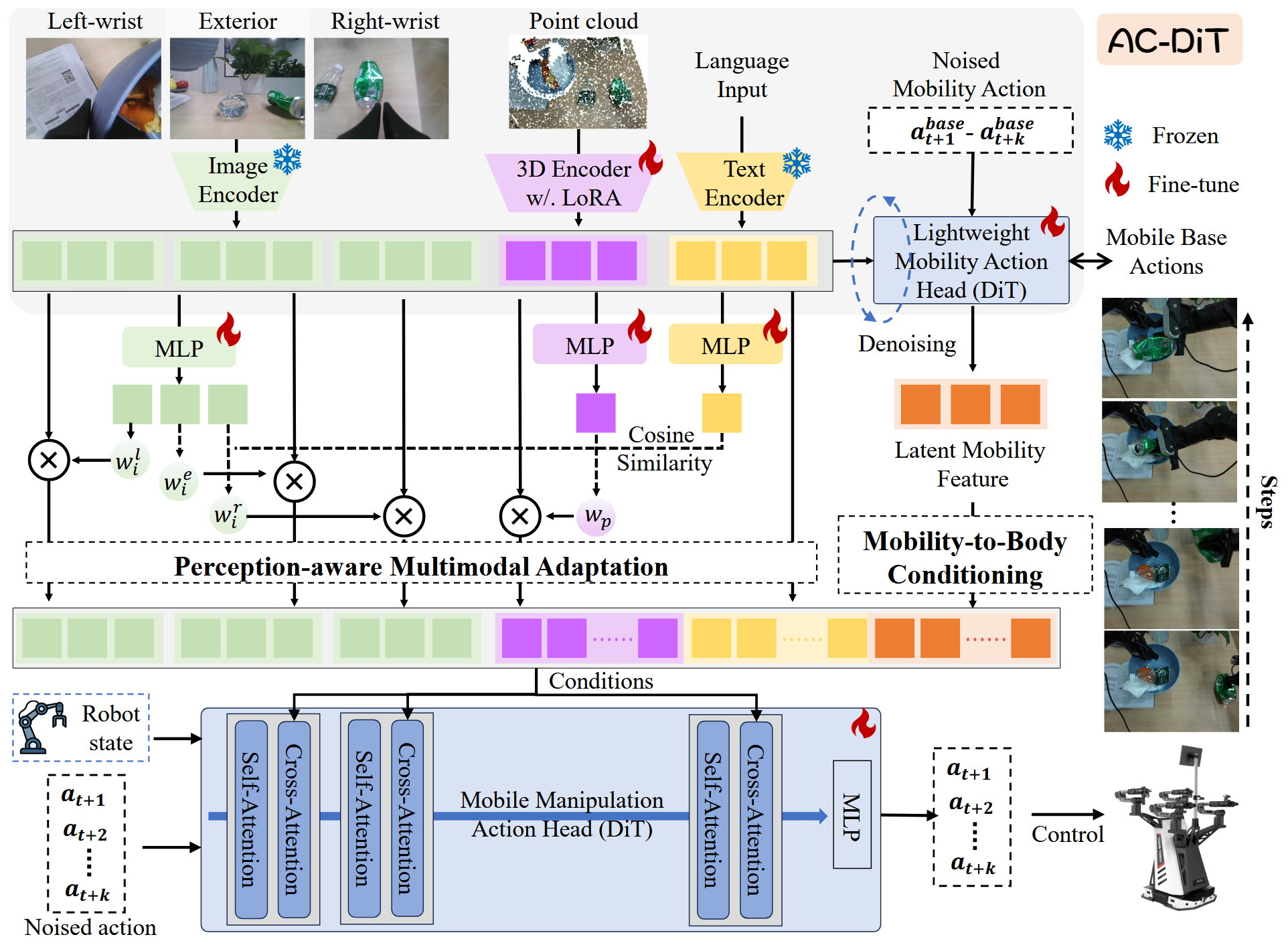
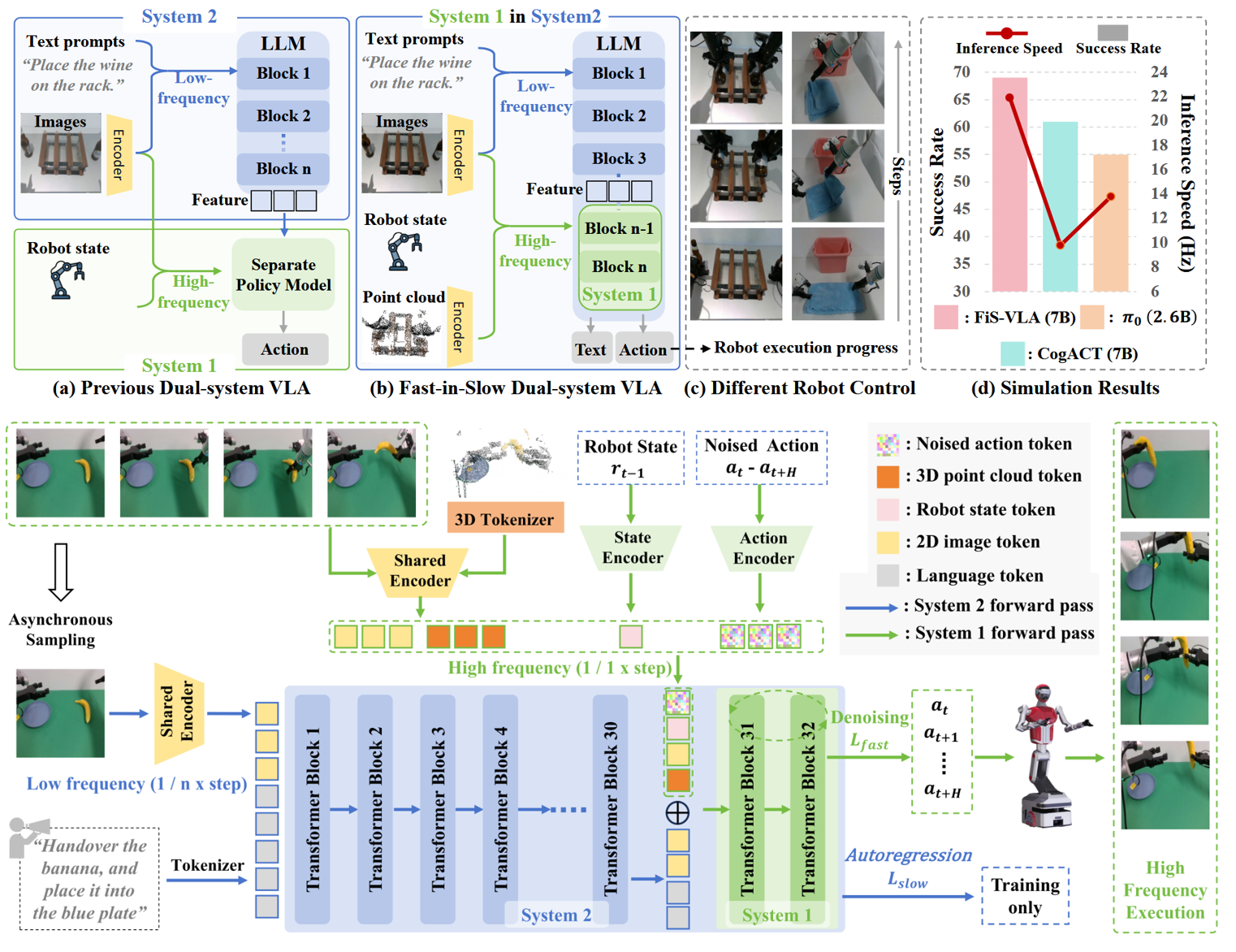
Unlike previous dual-system VLA methods that attach a separate policy head as System 1, FiS-VLA repurposes the final transformer blocks of an intact VLM as System 1, while retaining the full model for System 2 reasoning.
HybridVLA innovatively integrates diffusion and autoregressive action prediction within a single LLM, fully leveraging the continuity and probabilistic nature of diffusion alongside the reasoning capabilities of autoregressive modeling.
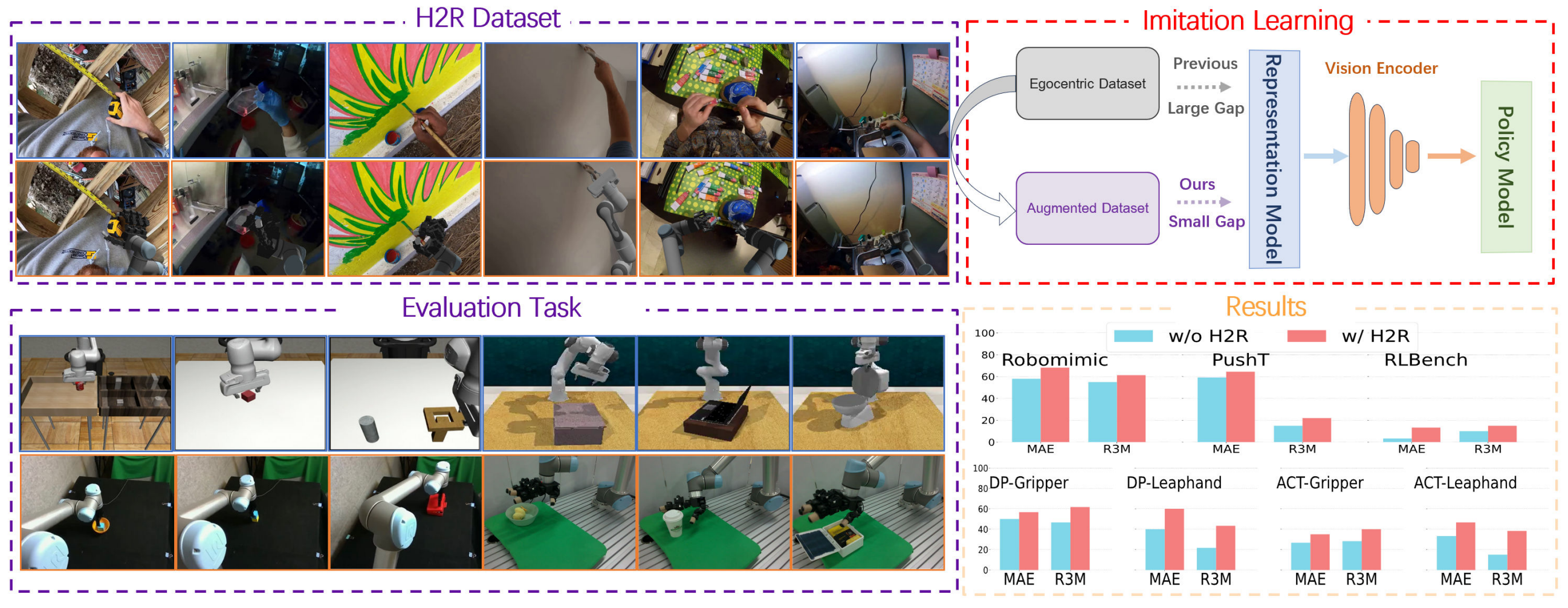
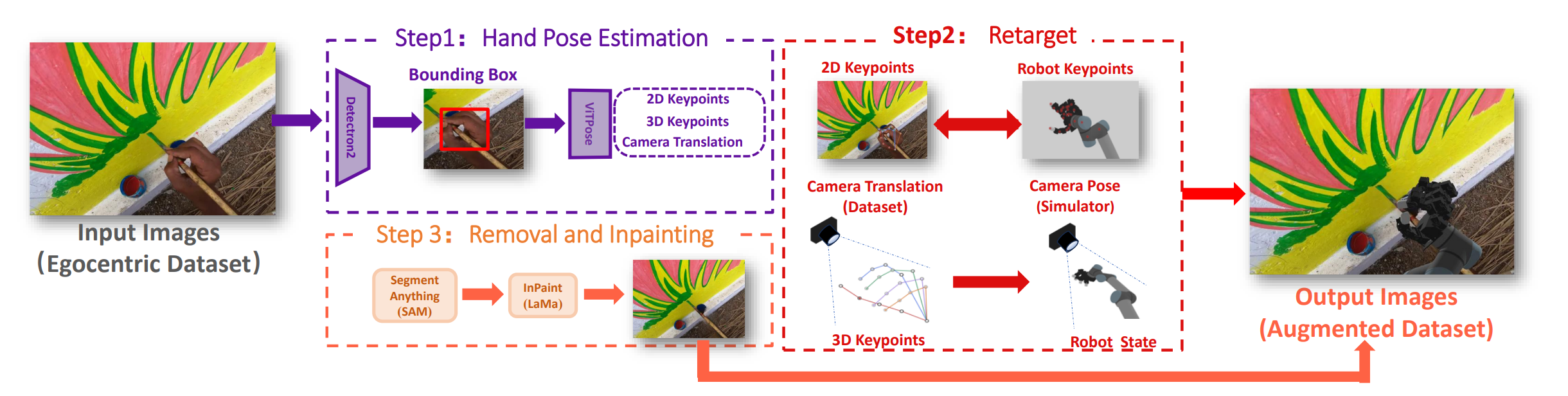
H2R is a simple data augmentation technique for robot pre-training from videos, which extracts the human hands from first-person videos and replaces them with those of different robots to generate new video data for pre-training.
Education
University of California, Berkeley Visiting Student, Berkeley Global Access (BGA) Program
2026.01 - Present
Peking University B.S. in Computer Science, Yuanpei College
2023.08 - Present
Research Experience
Beijing Innovation Center of Humanoid Robotics Research Intern
2025.08 - 2026.01
Research on Embodied AI and Robot Manipulation
AI2Robotics Research Intern, X-Lab
2025.06 - 2026.01
Focused on Vision-Language-Action (VLA) models
Peking University Research Intern, HMI (Human Machine Intelligence) Lab
2024.07 - Present